{kind=link}
In today’s competitive market, web crawling and web scraping have become an essential part of business growth, as the right data can be the difference between success and failure.
More than 54 industries require web scraping services and professionals in order to function. This data is based on job posting by Linkedin, Indeed, Glassdoor. This means almost all businesses are looking to scrap data in one way or another.

Fact: A whopping 5% of all the internet traffic is of web scraping (source)
But often crawling a website is not allowed by website owners, as it can lead to slowing down of the website, server crashing or damaging the website altogether. Crawling these websites can get you blocked.
Here are top tricks you can use to avoid getting blocked while crawling a website:
- Check robots.txt for crawling permission
- Slow down the scraping speed
- Use different proxies
- Keep changing your crawling pattern
- Avoid Honey traps
- Conclusion
Check robots.txt for crawling permission
Websites that do not want to be scrapped include permissions in robot.txt file. Always respect and see if permission to scrap is granted or denied. Only scrap websites that allow it.
Be respectful of the scraping rules a website has declared. Try to scrap in off-peak hours, so there is no extra load on the server, and website users can have a good browsing experience.
Slow down the scraping speed
Web scrapers can extract data very fast. Most scrapers try to extract as much data as possible. Since humans cannot match this speed, they easily get caught by the website and gets blocked. Train your scraper to mimic human behavior. How can you do that?
- Slow your scraper down.
- Add pauses between two clicks.
- Add up/down scrolls instead of clicking on the link immediately.
Use different proxies
When you crawl a website, your IP address can be seen. Making dozens of requests from the same IP will alert the webserver of non-human behavior, resulting in ban.
Test different proxy providers for web scraping before purchasing, it’s better when provider also provides proxy rotation and geographical targeting.
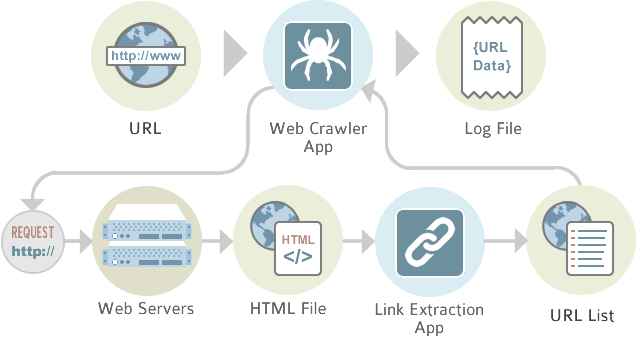
Keep changing your crawling pattern
If you keep your crawling pattern the same, it’s only a matter of time it will be judged as a crawler. You should keep changing the pattern to avoid getting blocked. Add random clicks and scrolls to keep it more realistic.
This randomness also should not be constant, keep changing the pattern. Think of how a regular user will use the website and try to replicate that behavior.
Avoid Honey traps
Honey traps are Html links that are invisible to users who are visiting the website, but scrappers can detect them. Clicking or engaging with those links sends an instant notification that a scrapper is in use. This will get you blocked immediately.
Try to avoid honey traps. This technique requires some technical knowledge to implement, that is why it is not used widely. Before starting your scraping, see and detect if there is any honeypot. Usually, the same technique will be used all over the website. For example, It can be through CSS (same color as the background, as a result not visible to a normal user). Or, a no display CSS style would be mentioned.
Conclusion
As scraping tools get smarter, websites also modify accordingly. Building a scraper is just the start. Hopefully, with all the tips and tricks mentioned in this article, you will be able to avoid getting blocked and save the hassle.